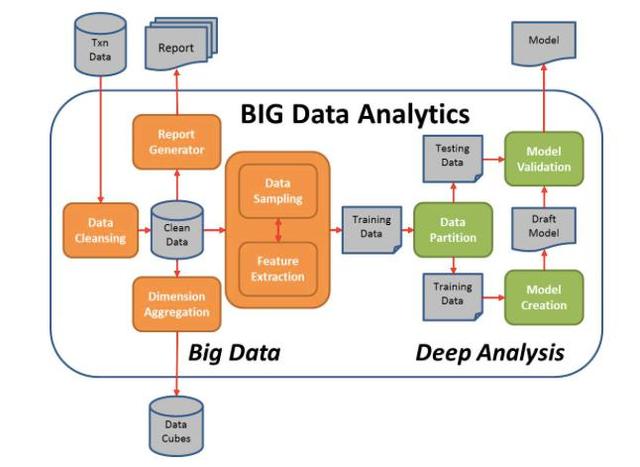
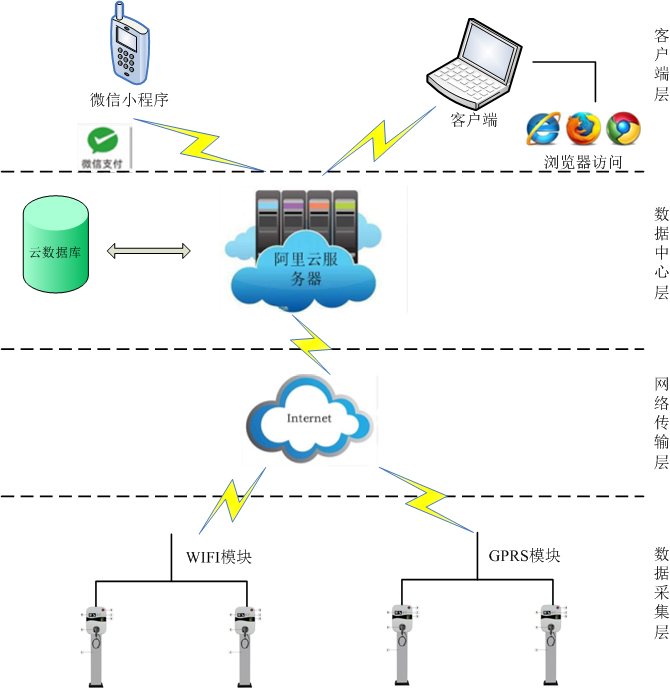
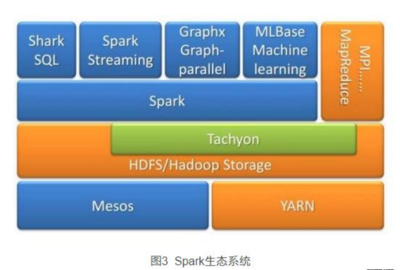
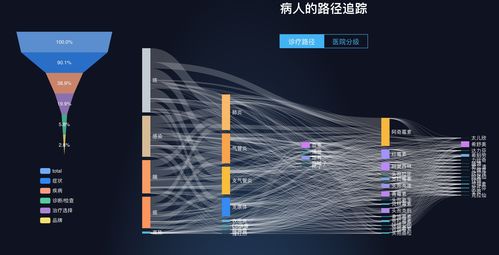
Flume在大數據生態中的數據采集實踐與應用
在大數據技術生態中,數據采集是整個數據處理流程的基石,它負責從各種分散、異構的數據源中高效、可靠地收集數據,并將其匯聚到中央存儲或處理系統中。Apache Flume作為一個高可用、高可靠、分布式的海量日志采集、聚合和傳輸系統,在這一環節扮演著至關重要的角色。本文將以技術博客的形式,探討Flume的核心概念、架構設計及其在實際大數據項目中的應用實踐。
一、Flume概述:數據流的可靠“搬運工”
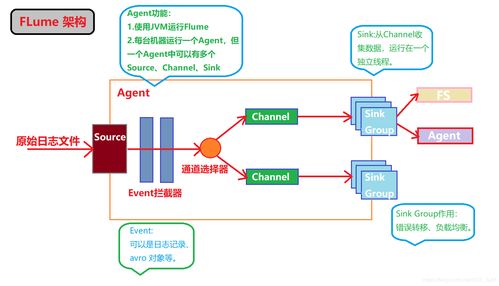
Apache Flume的設計初衷是為了解決大規模日志數據的實時采集問題。其核心思想是將數據流(Data Flow)抽象為“事件”(Event),并通過由“源”(Source)、“通道”(Channel)和“匯”(Sink)構成的“代理”(Agent)進行傳輸。這種清晰的架構使得Flume能夠靈活配置,適應從簡單單點采集到復雜、多層級的分布式采集場景。
二、核心組件深度解析
- Source(源):負責從數據源消費數據,并將其封裝為事件。Flume提供了豐富的Source類型,支持從文件(如
Exec Source執行命令輸出)、目錄(Spooling Directory Source監控目錄新增文件)、網絡端口(NetCat Source,Syslog TCP/UDP Source)乃至Kafka(Kafka Source)等系統接收數據。 - Channel(通道):作為事件的臨時存儲區,連接Source和Sink。它提供了數據的緩沖能力,確保在Sink處理速度跟不上時數據不會丟失。常用的Channel包括基于內存的
Memory Channel(性能高,但宕機會丟數據)和基于文件的File Channel(可靠性高,速度稍慢)。 - Sink(匯):負責從Channel中取出事件,并將其傳輸到下一個目的地或最終存儲庫。常見的目的地包括HDFS(
HDFS Sink)、HBase(HBaseSink)、另一個Flume Agent(Avro Sink)或消息系統如Kafka(Kafka Sink)。
三、架構設計與高級特性
一個典型的復雜數據流可能涉及多個Flume Agent,形成多級流(Multi-hop Flow)或扇入/扇出流(Fan-in / Fan-out Flow)。例如,多個前端服務器的Agent可以將日志匯聚到一個中央聚合Agent,再由其寫入HDFS,這體現了扇入流。
Flume的可靠性體現在其事務性的數據傳遞機制(基于Channel)和可配置的容錯與負載均衡(例如在Sink組中設置多個Sink實現故障轉移或負載均衡)。通過攔截器(Interceptor)鏈,用戶可以在事件傳輸過程中進行簡單的ETL操作,如添加時間戳、過濾特定事件或進行簡單的格式轉換。
四、實戰應用:從配置到問題排查
1. 配置實例:一個將本地日志目錄數據采集到HDFS的Agent配置示例片段如下:`properties
agent1.sources = src1
agent1.channels = ch1
agent1.sinks = sink1
agent1.sources.src1.type = spooldir
agent1.sources.src1.spoolDir = /var/log/app_logs
agent1.sources.src1.channels = ch1
agent1.channels.ch1.type = file
agent1.channels.ch1.checkpointDir = /data/flume/checkpoint
agent1.channels.ch1.dataDirs = /data/flume/data
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://namenode:8020/flume/events/%Y-%m-%d/
agent1.sinks.sink1.hdfs.filePrefix = logs-
agent1.sinks.sink1.channel = ch1`
2. 性能調優與監控:需根據數據量調整Channel容量(capacity)、事務容量(transactionCapacity)以及HDFS Sink的滾動策略(按時間、大小或事件數量)。通過集成JMX可以監控各項指標,如Channel的當前大小、Source/Sink的成功/失敗事件計數。
3. 常見問題:
* 數據重復:在采用File Channel且Sink未成功提交事務時,重啟后可能重發。需確保Sink目的地(如HDFS)的寫入是冪等的,或通過業務邏輯去重。
- 內存溢出:使用
Memory Channel且數據突發流量大時易發生。可切換為File Channel,或增加堆內存并調整垃圾回收策略。
- HDFS Sink小文件問題:過于頻繁的文件滾動會產生大量小文件。應合理配置
hdfs.rollInterval,hdfs.rollSize,hdfs.rollCount參數,在延遲、文件大小和數量間取得平衡。
五、與Kafka的協作模式
在現代Lambda或Kappa架構中,Flume常與Kafka協作。一種常見模式是使用Flume作為“生產者”,將數據采集并推送至Kafka主題(通過Kafka Sink),再由下游的流處理框架(如Spark Streaming、Flink)或另一個Flume Agent進行消費。這結合了Flume在采集端的穩定性和Kafka在高吞吐、分布式消息緩沖方面的優勢。
###
Apache Flume以其穩定、靈活的特性,成為了大數據數據采集層的一個經典選擇。盡管在極致的實時性要求下,可能面臨與更輕量級或定制化方案的競爭,但其在日志類、文件類數據向HDFS/HBase等系統遷移的場景中,依然發揮著不可替代的作用。深入理解其原理、合理設計數據流并做好監控調優,是保障大數據管道穩定高效運行的關鍵。
---
本文為技術博客分享,旨在梳理Flume的核心應用,具體配置與優化需結合實際生產環境。
如若轉載,請注明出處:http://www.acdmeg.cn/product/72.html
更新時間:2026-06-11 07:35:23